この投稿では、エンディアン(Endianness)について説明致します。
エンディアンとは、複数バイトで構成されるデータ(例:16ビット整数や32ビット整数など)をメモリや通信データに格納・送信する際のバイトの並び順を指します。コンピュータや通信機器同士でデータをやり取りする際に、エンディアンの違いによって正しくデータが解釈されないことがあるため、重要な概念です。
エンディアンには、主に次の2種類があります:
ビッグエンディアン(Big-Endian)
ビッグエンディアンでは、最上位バイト(もっとも重要なバイト)を先頭アドレスに配置します。これは、人間が通常読む数字の並び(左から右)に近く、可読性に優れているため、ネットワーク通信(たとえばTCP/IPプロトコル)ではこの方式が標準とされています。
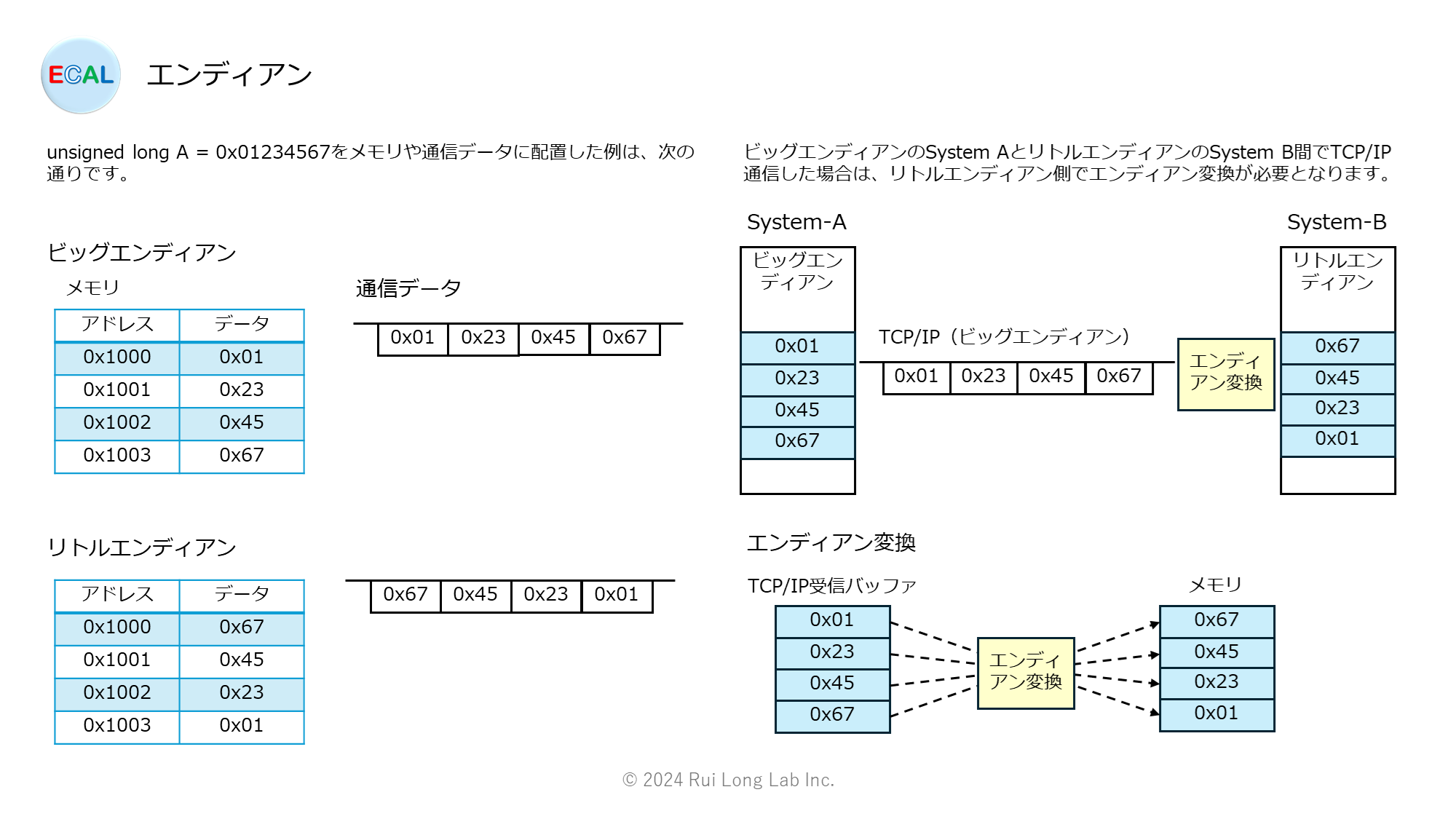
例:16進数の値 0x01234567 をビッグエンディアンでメモリに格納すると、01 23 45 67 という順番で並びます(低アドレス → 高アドレス)。
リトルエンディアン(Little-Endian)
リトルエンディアンでは、最下位バイト(もっとも重要度の低いバイト)を先頭アドレスに配置します。この方式は、数値演算の際に処理効率が良く、特に加算・減算のような演算処理が高速化しやすい特徴があります。そのため、Intel系CPU(x86、x64など)ではリトルエンディアンが採用されています。
例:16進数の値 0x01234567 をリトルエンディアンでメモリに格納すると、67 45 23 01 の順で並びます。
ご注意
次のような場合には、正しく変換処理を行わないとデータが誤って解釈されるため、対応が必要となります。
◆ 通信でバイト単位にデータを送受信する場合
通信プロトコルでは、データの送信順序が厳密に定められている場合が多く、一般的にはビッグエンディアン(ネットワークバイトオーダー)が使用されます。しかし、送信側や受信側がリトルエンディアンのシステムで動作している場合、そのまま送信するとバイトの順番が逆になってしまい、正しくデータが解釈されません。
注意ポイント:
送信時には、CPUのバイト順を通信仕様に合わせて変換(エンディアン変換)する必要があります。C言語などでは、htons() や htonl()(host to network short/long)などの関数が用意されています。
◆ リトルエンディアンで short型や long型 を char型のポインタ変数で操作する場合
C言語プログラミングなどでは、short や long などの多バイトデータを、char* 型ポインタで1バイトずつ操作することがあります。
リトルエンディアンでは、下位バイトが先頭に来るため、期待したバイト順で処理しないと誤動作の原因になります。
注意ポイント:char* でアクセスする際は、バイト順を意識してアクセスする必要があります。
例えば、short 型の2バイトデータから上位バイトだけ取り出したい場合、ビッグエンディアンとリトルエンディアンでは参照するバイト位置が異なります。
◆ 異なるエンディアンのシステムにプログラムを移植する場合
プログラムをリトルエンディアンのシステム(例:x86)からビッグエンディアンのシステム(例:一部の組込みCPU)へ移植する場合、以下のような影響が出る可能性があります。
- 構造体のバイト列の解釈が変わる(特に通信やファイルI/Oとの境界)
- バイナリファイルの読み書きが不正確になる(保存されたバイト順が異なるため)
- ネットワーク通信の整合性が崩れる(ハードウェアがバイト順を自動処理しない場合)
対策ポイント
- 明示的にバイト順を定義・変換する(シフト演算やマクロを使う)
- ポータブルなコードを書くために、
uint8_t、uint16_tなど固定サイズの型を使い、バイト順を手動で制御する