本文将对字节序(Endianness)进行说明。
字节序(Endianness)是指在将由多个字节组成的数据(例如16位整数或32位整数等)存储或传输到内存或通信数据时,字节的排列顺序。在计算机或通信设备之间交换数据时,由于字节序的不同,可能会导致数据无法正确解析,因此这是一个非常重要的概念。
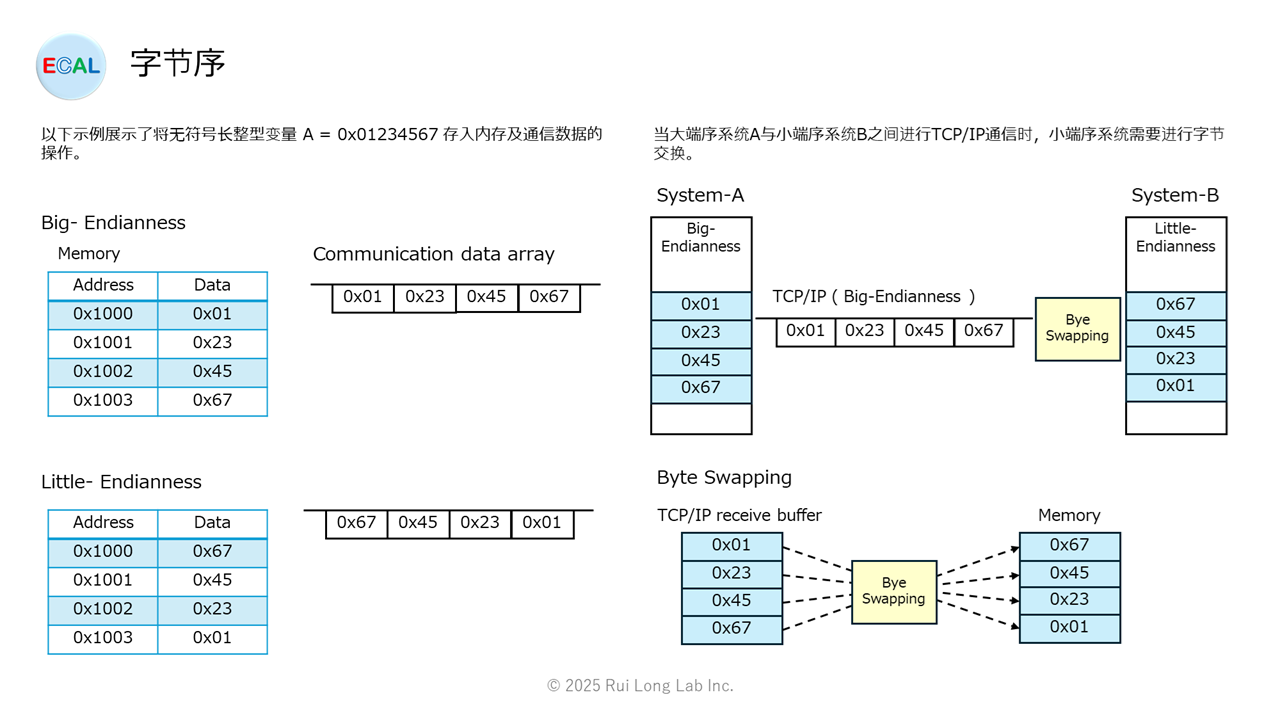
字节序主要有以下两种类型:
大端序(Big-Endian)
在大端序中,将最高位字节(最重要的字节)放置在地址的起始位置。这种方式与人类通常阅读数字的顺序(从左到右)较为接近,因此具有较高的可读性。因此,在大多数网络通信协议(例如TCP/IP协议)中,这种方式被视为标准。
例如:将十六进制值 0x01234567 以大端序存储到内存中时,其顺序为 01 23 45 67(从低地址到高地址)。
小端序(Little-Endian)
小端序中,将最低位字节(即重要性最低的字节)放置在地址的起始位置。这种方式在进行数值运算时具有较高的处理效率,尤其在加法和减法等运算处理中更易于实现高速化。因此,Intel系列CPU(如x86、x64等)采用了小端序。
例如:将十六进制值 0x01234567 以小端序存储在内存中时,其字节顺序为 67 45 23 01。
注意事项:
在以下情况下,如果不正确地进行转换处理,数据可能会被错误地解释,因此需要采取相应的措施。
◆ 通过通信以字节为单位发送和接收数据时
在通信协议中,数据的传输顺序通常有严格的规定,一般采用大端序(网络字节顺序)。然而,如果发送方或接收方运行在小端序系统上,直接传输数据会导致字节顺序颠倒,从而无法正确解析数据。
注意:
在发送数据时,需要将CPU的字节序转换为符合通信规范的字节序(即进行字节序转换)。在C语言等编程语言中,提供了htons()和htonl()(主机到网络短整型/长整型)等函数来实现这一转换。
◆ 在小端序中,使用字符指针变量操作short型或long型时
在C语言编程等场景中,有时会使用char*类型指针对short或long等多字节数据进行逐字节操作。在小端序中,低字节位于首位,因此若未按预期字节顺序进行处理,可能导致错误运行。
注意:
使用 char* 访问时,需要注意字节顺序。例如,当需要从 short 类型的 2 字节数据中提取高位字节时,大端序和小端序的字节位置会有所不同。
◆ 不同字节序的系统之间移植程序时
将程序从小端系统(例如x86)移植到大端系统(例如某些嵌入式CPU)时,可能会产生以下影响。
- 结构体的字节序列解释发生变化(尤其是在通信或文件I/O的边界处)
- 二进制文件的读写操作可能出现不准确的情况(由于保存的字节顺序不同)
- 网络通信的完整性被破坏(当硬件无法自动处理字节顺序时)
对策要点:
- 显式地定义和转换字节顺序(使用移位运算或宏)
- 为了编写可移植的代码,使用uint8_t、uint16_t等固定大小的类型,并手动控制字节顺序。